Design of the CRLite Infrastructure
Published 2020-12-01 originally at Mozilla's Security Blog and cross-posted here.
Firefox is the only major browser that still evaluates every website it connects to whether the certificate used has been reported as revoked. Firefox users are notified of all connections involving untrustworthy certificates, regardless the popularity of the site. Inconveniently, checking certificate status sometimes slows down the connection to websites. Worse, the check reveals cleartext information about the website you’re visiting to network observers.
We’re now testing a technology named CRLite which provides Firefox users with the confidence that the revocations in the Web PKI are enforced by the browser without this privacy compromise. This is a part of our goal to use encryption everywhere. (See also: Encrypted SNI and DNS-over-HTTPS)
The first three posts in this series are about the newly-added CRLite technology and provide background that will be useful for following along with this post:
- Introducing CRLite: All of the Web PKI’s revocations, compressed,
- CRLite: Speeding Up Secure Browsing, and specifically useful is
- The End-to-End Design of CRLite.
This blog post discusses the back-end infrastructure that produces the data which Firefox uses for CRLite. To begin with, we’ll trace that data in reverse, starting from what Firefox needs to use for CRLite’s algorithms, back to the inputs derived from monitoring the whole Web PKI via Certificate Transparency.
Tracing the Flow of Data
Individual copies of Firefox maintain in their profiles a CRLite database which is periodically updated via Firefox’s Remote Settings. Those updates come in the form of CRLite filters and “stashes”.
Filters and Stashes
The general mechanism for how the filters work is explained in Figure 3 of The End-to-End Design of CRLite.
Introduced in this post is the concept of CRLite stashes. These are lists of certificate issuers and the certificate serial numbers that those issuers revoked, which the CRLite infrastructure distributes to Firefox users in lieu of a whole new filter. If a certificate’s identity is contained within any of the issued stashes, then that certificate is invalid.
Combining stashes with the CRLite filters produces an algorithm which, in simplified terms, proceeds like this:
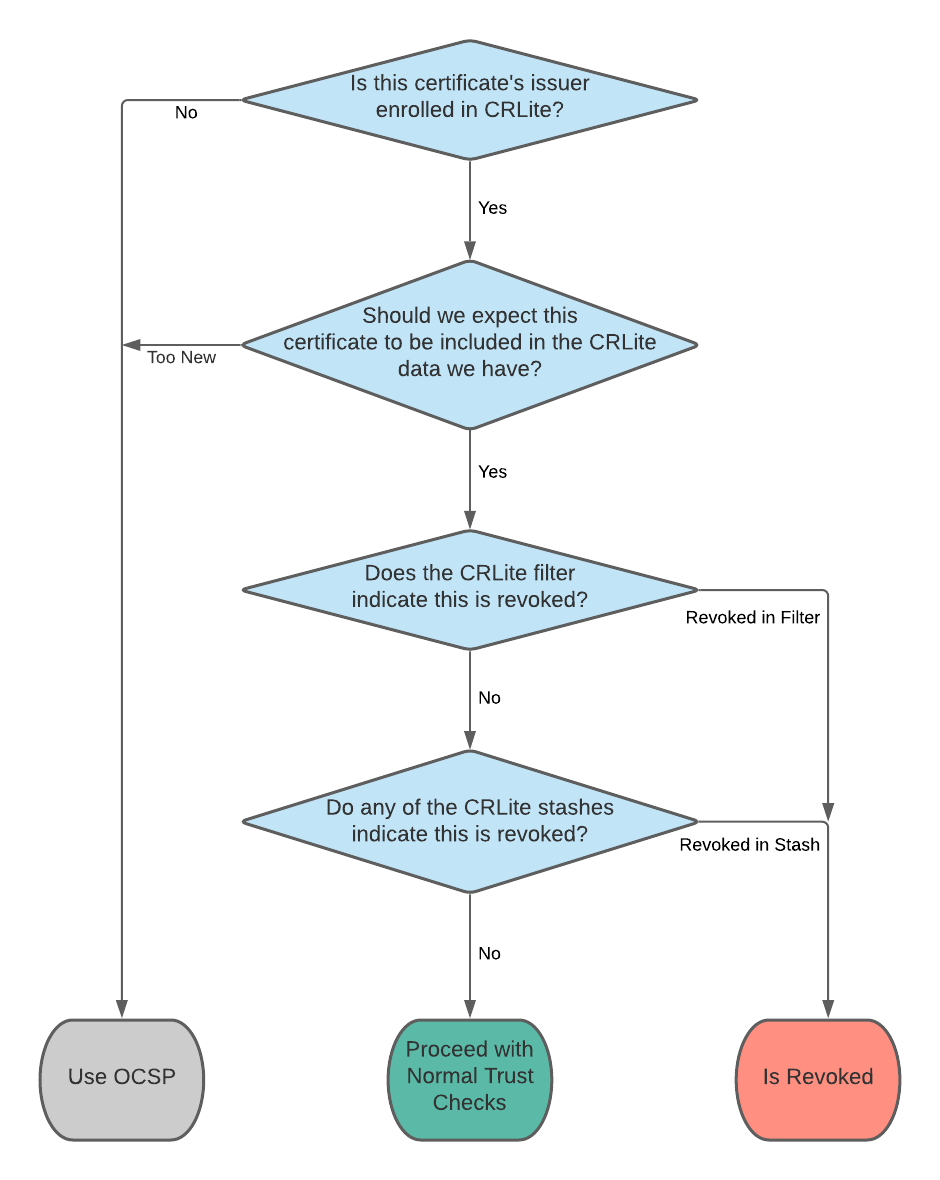
Every time the CRLite infrastructure updates its dataset, it produces both a new filter and a stash containing all of the new revocations (compared with the previous run). Firefox’s CRLite is up-to-date if it has a filter and all issued stashes for that filter.
Enrolled, Valid and Revoked
To produce the filters and stashes, CRLite needs as input:
- The list of trusted certificate authority issuers which are enrolled in CRLite,
- The list of all currently-valid certificates issued by each of those enrolled certificate authorities, e.g. information from Certificate Transparency,
- The list of all unexpired-but-revoked certificates issued by each of those enrolled certificate authorities, e.g. from Certificate Revocation Lists.
These bits of data are the basis of the CRLite decision-making.
The enrolled issuers are communicated to Firefox clients as updates within the existing Intermediate Preloading feature, while the certificate sets are compressed into the CRLite filters and stashes. Whether a certificate issuer is enrolled or not is directly related to obtaining the list of their revoked certificates.
Collecting Revocations
To obtain all the revoked certificates for a given issuer, the CRLite infrastructure reads the Certificate Revocation List (CRL) Distribution Point extension out of all that issuer’s unexpired certificates and filters the list down to those CRLs which are available over HTTP/HTTPS. Then, every URL in that list is downloaded and verified: Does it have a valid, trusted signature? Is it up-to-date? If any could not be downloaded, do we have a cached copy which is still both valid and up-to-date?
For issuers which are considered enrolled, all of the entries in the CRLs are collected and saved as a complete list of all revoked certificates for that issuer.
Lists of Unexpired Certificates
The lists of currently-valid certificates and unexpired-but-revoked certificates have to be calculated, as the data sources that CRLite uses consist of:
- Certificate Transparency’s list of all certificates in the WebPKI, and
- All the published certificate revocations from the previous step.
By policy now, Certificate Transparency (CT) Logs, in aggregate, are assumed to provide a complete list of all certificates in the public Web PKI. CRLite then filters the complete CT dataset down to certificates which haven’t yet reached their expiration date, but which have been issued by certificate authorities trusted by Firefox.
Filtering CT data down to a list of unexpired certificates allows CRLite to derive the needed data sets using set math:
- The currently-valid certificates are those which are unexpired and not included in any revocation list,
- The unexpired-but-revoked certificates are those which are unexpired and are included in a revocation list.
The CT data simply comes from a continual monitoring of the Certificate Transparency ecosystem. Every known CT log is monitored by Mozilla’s infrastructure, and every certificate added to the ecosystem is processed.
The Kubernetes Pods
All these functions are orchestrated as four Kubernetes pods with the descriptive names Fetch, Generate, Publish, and Sign-off.
Fetch
Fetch is a Kubernetes deployment, or always-on task, which constantly monitors Certificate Transparency data from all Certificate Transparency logs. Certificates that aren’t expired are inserted into a Redis database, configured so that certificates are expunged automatically when they reach their expiration time. This way, whenever the CRLite infrastructure requires a list of all unexpired certificates known to Certificate Transparency, it can iterate through all of the certificates in the Redis database. The actual data stored in Redis is described in our FAQ.

Generate
The Generate pod is a periodic task, which currently runs four times a day. This task reads all known unexpired certificates from the Redis database, downloads and validates all CRLs from the issuing certificate authorities, and synthesizes a filter and a stash from those data sources. The resulting filters and stashes are uploaded into a Google Cloud Storage bucket, along with all the source input data, for both public audit and distribution.

Publish
The Publish task is also a periodic task, running often. It looks for new filters and stashes in the Google Cloud Storage bucket, and stages either a new filter or a stash to Firefox’s Remote Settings when the Generate task finishes producing one.

Sign-Off
Finally, a separate Sign-Off task runs periodically, also often. When there is an updated filter or stash staged at Firefox’s Remote Settings, the sign-off task downloads the staged data and tests it, looking for coherency and to make sure that CRLite does not accidentally include revocations that could break Firefox. If all the tests pass, the Sign-Off task approves the new CRLite data for distribution, which triggers Megaphone to push the update to Firefox users that are online.

Using CRLite
We recently announced in the mozilla.dev.platform mailing list that Firefox Nightly users on Desktop are relying on CRLite, after collecting encouraging performance measurements for most of 2020. We’re working on plans to begin tests for Firefox Beta users soon. If you want to try using CRLite, you can use Firefox Nightly, or for the more adventurous reader, interact with the CRLite data directly.
Our final blog post in this series, Part 5, will reflect on the collaboration between Mozilla Security Engineering and the several research teams that designed and have analyzed CRLite to produce this impressive system.