Analyzing Let's Encrypt statistics via Map/Reduce
Published 2017-05-16
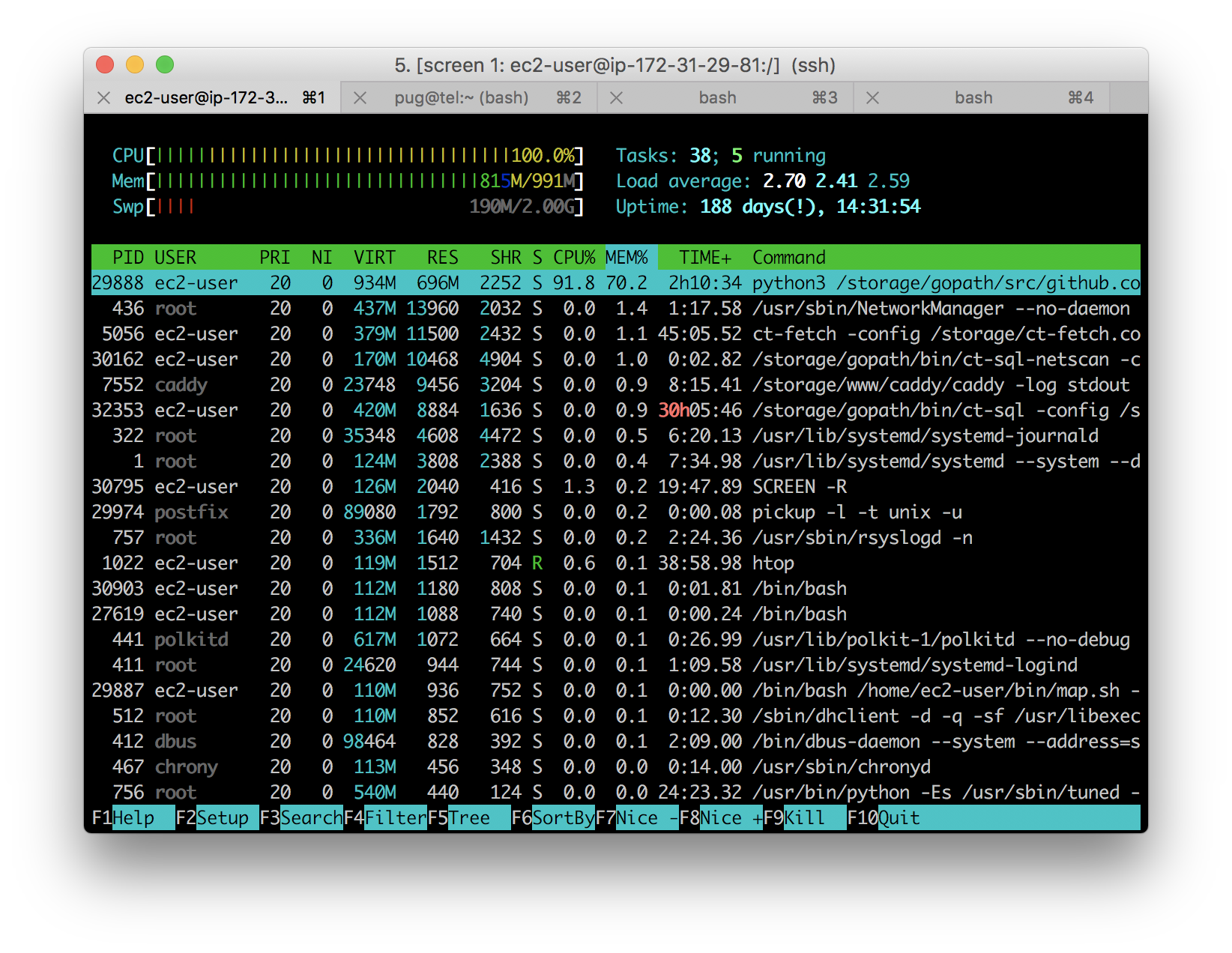
I've been supplying the statistics for Let's Encrypt since they've launched. In Q4 of 2016 their volume of certificates exceeded the ability of my database server to cope, and I moved it to an Amazon RDS instance.
Ow.
Amazon's RDS service is really excellent, but paying out of pocket hurts.
I've been re-building my existing Golang/MySQL tools into a Golang/Python toolchain at slowly over the past few months. This switches from a SQL database with flexible, queryable columns to a EBS volume of folders containing certificates.
The general structure is now:
/ct/state/Y3QuZ29vZ2xlYXBpcy5jb20vaWNhcnVz
/ct/2017-08-13/qEpqYwR93brm0Tm3pkVl7_Oo7KE=.pem
/ct/2017-08-13/oracle.out
/ct/2017-08-13/oracle.out.offsets
/ct/2017-08-14/qEpqYwR93brm0Tm3pkVl7_Oo7KE=.pemFetching CT
Underneath /ct/state exists the state of the log-fetching utility, which is now a Golang tool named ct-fetch. It's mostly the same as the ct-sql tool I have been using, but rather than interact with SQL, it simply writes to disk.
This program creates folders for each notAfter date seen in a certificate. It appends each certificate to a file named for its issuer, so the path structure for cert data looks like:
/BASE_PATH/NOT_AFTER_DATE/ISSUER_BASE64.pemThe Map step
A Python 3 script ct-mapreduce-map.py processes each date-named directory. Inside, it reads each .pem and .cer file, decoding all the certificates within and tallying them up. When it's done in the directory, it writes out a file named oracle.out containing the tallies, and also a file named oracle.out.offsets with information so it can pick back up later without starting over.
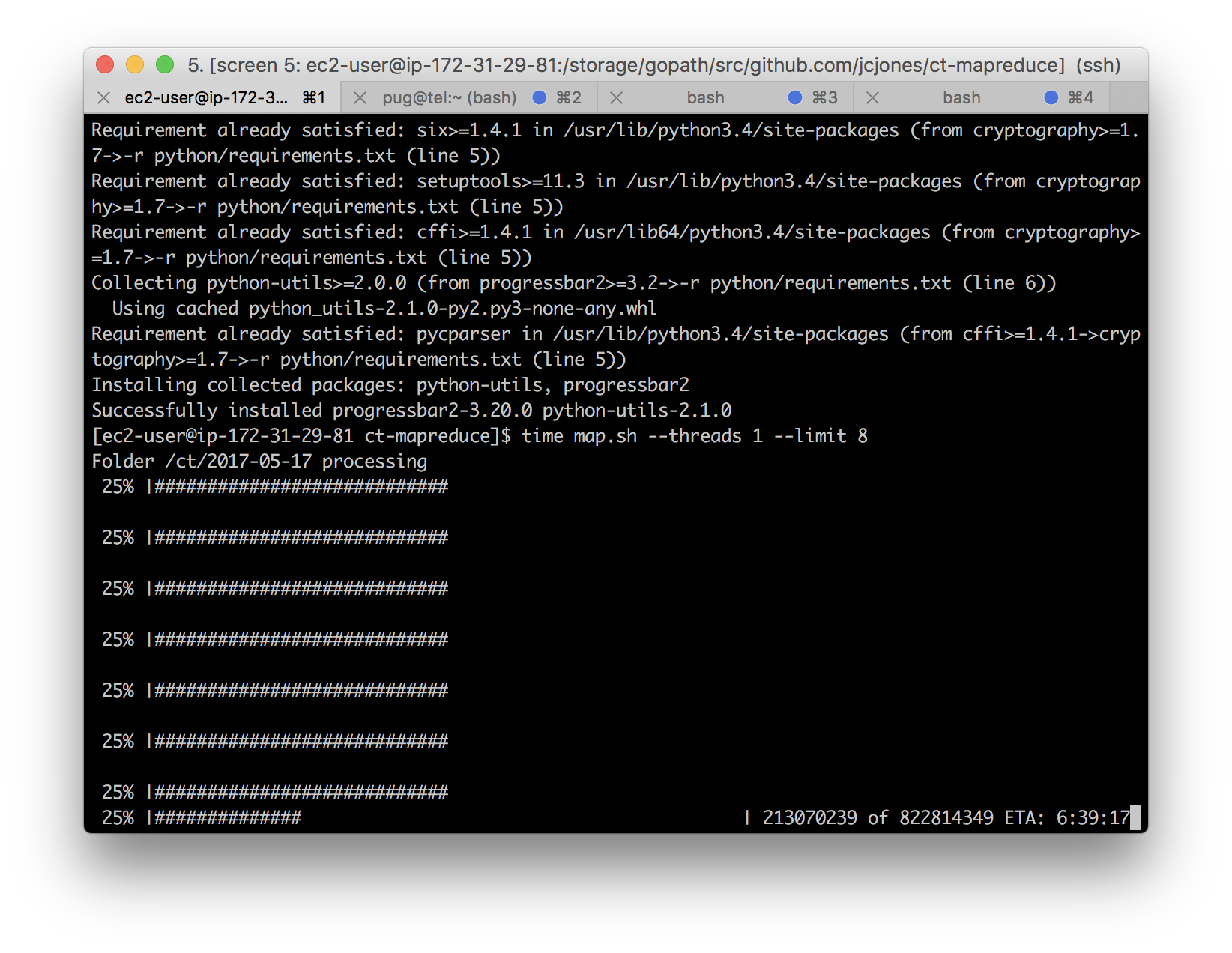
The tallies contain, for each issuer:
- The number of certificates issued each day
- The set of all FQDNs issued
- The set of all Registered Domains (eTLD + 1 label) issued
The resulting oracle.out is large, but much smaller than the input data.
The Reduce step
Another Python 3 script ct-mapreduce-reduce.py finds all oracle.out files in directories whose names aren't in the past. It reads each of these in and merges all the tallies together.
The result is the aggregate of all of the per-issuer data from the Map step.
This will get converted then into the data sets currently available at https://ct.tacticalsecret.com/
State
I'm not yet to the step of synthesizing the data sets; each time I compare this data with my existing data sets there are discrepancies - but I believe I've improved my error reporting enough that after another re-processing, the data will match.
Performance
Right now I'm trying to do all this with a free-tier AWS EC2 instance and 100 GB of EBS storage; it's not currently clear to me whether that will be able to keep up with Let's Encrypt's issuance volume. Nevertheless, even an EBS-optimized instance is much less expensive than an RDS instance, even if the approach is less flexible.